Sharing our legal AI lessons at Stanford Law School’s AI & Access to Justice Summit
by Chris McGrath | Nov 24, 2025
Last week, I had the privilege of presenting at the AI and Access to Justice Summit at Stanford Law School. My talk centered on the lessons learned from our journey building and iterating on Beagle+, a production legal AI chatbot for People's Law School in British Columbia.

Chris McGrath at Stanford, presenting "21 months of Beagle+ — lessons from a production legal AI chatbot"
Key takeaways
21 months after launching Beagle+, a production legal AI chatbot, we've learned some valuable lessons that might help other legal organizations considering similar projects.
Here are our three biggest insights:
For everyday legal problems, AI can answer questions as well as a lawyer can.
Testing and monitoring is critical, but it's easy to go overboard.
Your biggest asset is your best, unique content.

Margaret Hagan, Executive Director of the Legal Design Lab at Stanford Law School; Chris McGrath, Founder at Tangowork; Erik Bornmann, Director of CLEO's Guided Pathways (and valued Tangowork client!)
The Beagle+ journey so far
Launched in February 2024, Beagle+ is a RAG (Retrieval Augmented Generation) chatbot that answers questions for all common types of legal problems in British Columbia.
The results have been encouraging. In 21 months:
We're holding steady at over 99% legal accuracy.
Beagle+ has helped with more than 13,000 questions.
81 percent of people have said Beagle+ was helpful (based on 3,200+ datapoints).
Our tech stack includes:
OpenAI as the LLM
Pinecone as the vector database
Contentful as our CMS
NextJS for the front end
Vercel as web host
Langfuse for prompt management, conversation review and LLM-as-judge evaluators.
1. For everyday legal problems, AI can answer questions as well as a lawyer can.
This is our most impactful finding. Our accuracy improved dramatically during development, starting at 70% accuracy in pre-launch testing and reaching 99% by launch.
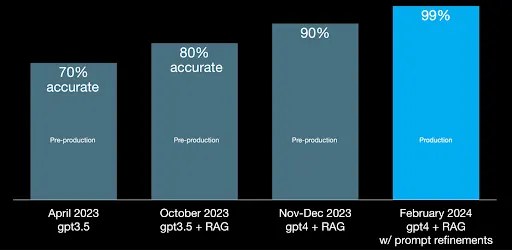
After going live and incorporating real-world feedback, we maintained 99% accuracy.

The key was iterative testing and refinement. Each round of testing helped us identify weak points in our system and improve our source content, our system prompts, and our chatbot logic.
2. Testing and monitoring is critical — but it's easy to go overboard.
The lawyers at People's Law School developed a comprehensive 42-question dataset to evaluate Beagle+'s performance. (See the dataset on JusticeBench.) These 42 test questions were based on actual questions received by People's Law School, selected to reflect the diversity of problems people face.
Each question in our dataset has an ideal response and key points that any good answer should include. Lawyers assessed responses on both safety and value, which proved crucial for maintaining quality. We tested many different configurations and published a dataset that shows our results with 7 different combinations.
Safety and value improvements
Through our testing journey, responses became more consistently safe and valuable. This required dedicated effort and systematic evaluation. We continue to use our testing dataset to improve Beagle+, most recently using it to evaluate GPT 4.1 in May 2025.

The top bar shows the ideal response (all green, or "Safe"). Moving down the chart, each successive bar shows a testing configuration with less and less red ("Unsafe").

The top bar shows the ideal, "very valuable" response. Moving down the chart, each bar shows a testing configuration. The bottom bar shows the chatbot as of May 2025, with 100% "valuable" or "very valuable" responses.
We monitor all conversations through Langfuse, an LLM engineering platform, which gives us ongoing insights into real-world performance.
How to go overboard
It's surprisingly easy to over-engineer your testing and monitoring. You could:
Formally test every possible LLM combination
Score against overly complex rubrics
Review every single conversation
Implement multiple LLM-as-judge evaluators with granular scoring.
What actually worked for us:
Fiddled with LLM settings in a playground, then formally tested just a few good options.
Scored on two dimensions: Safety (Safe, Unsafe, Very unsafe) and Value (Very valuable, Valuable, Not valuable).
Reviewed every single conversation initially, then gradually reduced based on an LLM-generated Severity score.
Used just a few LLM-as-judge evaluators with coarse scoring.
3. Your biggest asset is your best, unique content.
People's Law School has the best content that exists on the topics they cover. That ensures that Beagle+ outperforms ChatGPT on those topics.
As ChatGPT continues to improve, though, niche and proprietary content becomes indispensable.
For example, Beagle+ can answer very specific questions about British Columbia probate forms because we developed a special method to ingest these forms and then "show" them to the large language model when a person asks a probate-related question.
Where to from here?
Looking forward, we're hoping to collaborate on research with a university that explores the quality of chatbot responses to legal questions compared to human lawyers. This kind of comparative research could provide valuable insights for the broader legal AI community and help establish benchmarks for quality and safety in legal AI applications.
The journey so far has taught us that building effective legal AI is about understanding your unique value, testing systematically without overdoing it, and always keeping the end user's needs at the center of your development process.